Behatolást érzékelő intelligens algoritmusok
h, 2004-03-29 00:10 - palacsint
A Kecskeméti Főiskola GAMF karának 2003/2004-es tanévének tavaszi szemeszterében, Mesterséges Intelligencia c. tantárgyból meghirdetett tanulmányi versenyére beadott irodalomfeldolgozási tanulmányunk.
Knight, palacsint
knight AT message.hu, palacsint AT freemail.hu
Kivonat. A cikk elején általánosan bemutatunk egy intelligens behatolás-érzékelő rendszert, majd két tanulmányt, melyeket a Koreai Yonsei Egyetem Számítógéptudományi Karának kutatói 2003-ban illetve 2004-ben publikáltak. A cikkek kiválasztásában aktualitásuk mellett létező gyakorlati megvalósításuk döntött.
2004. március 29.
Megjegyzés: A képek sajnos nem a legjobb minőségűek, illetve nem a legjobban illeszkednek a html környezetbe. A nagyon problémásak (amelyek kis méretben olvashatatlanok) linkelve vannak, így teljes méretben, olvashatóan is megtekinthetőek.
1. Bevezetés
A számítógépes hálózatok egyre szélesebb körű elterjedésével az ilyen rendszerekbe történő behatolási kísérletek száma is folyamatosan nő. Mivel e rendszerek egyre több és komolyabb feladatot látnak el, így a megszerezhető információk értéke, illetve a szolgáltatások leállása által okozott presztízsveszteség is egyre nagyobb. Ezek megakadályozására különféle védelmi rendszerek használata vált általánossá. A legáltalánosabban használt védelmi rendszerek a csomagszűrő tűzfalak, melyek az IP csomagok fejlécét vizsgálva egy előre meghatározott szabályrendszer alapján döntenek arról, hogy egy adott csomagot átengednek-e, vagy sem. Egy összetett rendszer ezzel szemben már tartalomszűrést is végez, azaz a csomagokban lévő adatokat is elemzi különféle szempontok alapján, mint például vírusellenőrzés, vagy a kéretlen levelek szűrése. Működésük során már egy kisebb hálózattal bíró szervezet eszközei is képesek hatalmas mennyiségű információt előállítani, amelyek utalhatnak egy lehetséges behatolásra. Ekkora mennyiségű adat manuális feldolgozása a hálózatért felelős személyek számára általában képtelenség, ezért felmerült az igény olyan rendszerek iránt, amelyek ezen információkat feldolgozva, behatolási kísérlet esetén értesítik a megfelelő személyeket. A behatolást érzékelő rendszerek (IDS - Intrusion Detection System) ezen információk alapján próbálják eldönteni, valóban behatolási kísérlet történt-e, ezzel könnyítve az emberek munkáját.
2. A probléma és a cél
Mindig vannak olyan emberek, akik megpróbál(hat)nak a meglévő - esetlegesen nulla - jogosultságuknál többet szerezni egy-egy számítógépre, számítógépes rendszerre. Pontosabban nem csak emberek, különféle férgek, vírusok is terjednek számítógépről-számítógépre, amelyek nem az eredeti céljára használják az erőforrásokat, és valamilyen ügyes technikával illetve hiba kihasználásával több dologra képesek, mint amihez joguk lenne. A cél minden egyes ilyen - sikeres és sikertelen - behatolási kísérlet jelzése az illetékes személyeknek, illetve a behatolások megakadályozása. Nyilvánvaló, hogy nem lehetséges minden ilyen esemény jelzése, de törekedni kell a minél nagyobb hatékonyságra, amely a hamis riasztások (false positive) és az elmaradt (de egyébként szükséges) riasztások (false negative) számában nyilvánul meg.
3. A behatolást érzékelő rendszerek jelenlegi helyzete
A mai IDS-ek képességei általában erősen a szekvenciafelismerésre korlátozódnak. Nem eléggé intelligensek, hogy megbízhatóan jelezzenek egy támadást, korrelálják a különböző helyekről érkező információkat és a támadás mértékének, illetve a jelzés megbízhatóságának függvényében ellenintézkedéseket tegyenek a támadás kivédésére, figyelembe véve a különösen fontos rendszereket.
4. Egy intelligens rendszer vázlata
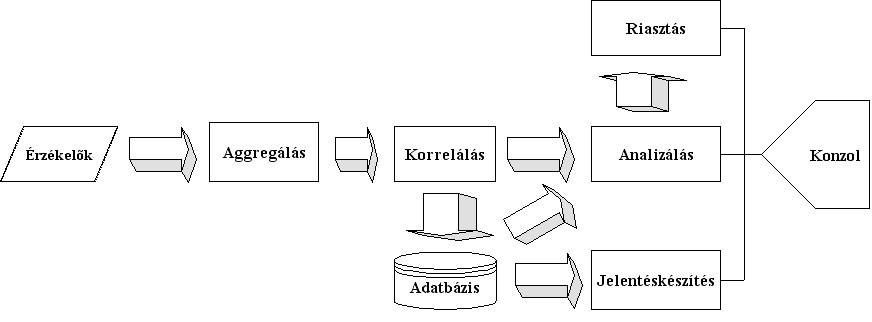
1. ábra: Egy intelligens rendszer vázlata
4.1. Érzékelők
Az érzékelők valósítják meg a naplóadatok bevitelét a rendszerbe. Ezek az érzékelők lehetnek tűzfalak, útválasztók, hálózati vagy host alapú IDS-ek és alkalmazásnaplók is. Minden érzékelő közvetlenül kommunikál a rendszer aggregáló moduljával. Egy jó IDS-nek számos különféle érzékelőt kell támogatnia.
4.2. Aggregálás
Ez az a hely, ahova az érzékelők által begyűjtött információk naplózásra kerülnek. Különböző módok vannak az információk kinyerésére az érzékelőktől függően. Ezek összegyűjthetőek SNMP-n, syslog-on, ágenseken vagy más protokollokon keresztül is. Az aggregálás a különféle helyekről származó információk összegyűjtését és normalizálását jelenti. A normalizálás alatt pedig az ugyanolyan típusú, de más gyártótól származó naplóbejegyzések közös formátumra hozását értjük.
4.3. Korrelálás
Közeli rokonság van a korreláció és az analizálás között. A fő különbség, hogy az analizáló folyamat gondoskodik egy szabályalapú felületről, és képes nem aggregált információkat felhasználni a számítási folyamatban. A korrelációs modul fő feladata az események feldolgozása és a köztük lévő kapcsolat keresése. Ez alapulhat az időbélyegek, cél-, és forráscímek, illetve a naplózott információk alapján megállapított más logikai kapcsolatok kombinációján. A korrelált események naplózott események, amelyek valamilyen összefüggés alapján logikailag csoportosítva vannak. Egy másik, összetett oldala a korrelációnak, hogy képes felismerni a viselkedési mintázatokat a különböző érzékelők között. Például, ha egy adott gépről hat sikertelen bejelentkezést kezdeményeznek, akkor ezek - feltéve, hogy különböző gépekről van szó - hat különböző naplóban fognak megjelenni. Amint ezen információk egy helyen, korrelált formában jelentkeznek rögtön szembetűnik, hogy valamiféle probléma van, míg külön-külön valószínűleg a legtöbb adminisztrátor figyelmen kívül hagyná őket.
4.4. Riasztás
A riasztást végző folyamat biztosítja, hogy az adminisztrátorok felfigyeljenek bizonyos eseményekre. Ez elképzelhető képernyőn felvillanó üzenetként, e-mailként és számtalan más formában.
4.5. Jelentéskészítés
A jelentéskészítés feltétlenül szükséges a hosszú távú trendek felismeréséhez és képes szabatos információkkal ellátni a menedzsmentet.
5. Érzékelők csoportosítása
5.1. Beszerzés szerint
A leggyakrabban az információforrásuk módja szerint szokták csoportosítani az IDS-eket. Néhány IDS lehallgatja és analizálja az egész hálózat forgalmát, hogy megtalálják a támadókat. Más IDS-ek az operációs rendszer által generált naplófájlokat veszik szemügyre, míg megint mások az alkalmazások által készített naplókat figyelve kutatnak a behatolások nyomai után.
Hálózat-alapú IDS-ek (Network based IDS, NIDS)
A kereskedelmi forgalomban kapható IDS-ek nagy része ebbe a csoportba tartozik. Egy ilyen IDS több másik gépet is tud figyelni, úgy, hogy az adott hálózati szegmensben közlekedő csomagokat elkapják és analizálják. Könnyen el lehet őket rejteni a hálózaton passzív eszközként, ha kifele menő forgalmat nem generálnak, láthatatlanok lehetnek egy külső szemlélő számára. A titkosított forgalom, a switchelt hálózatok megfigyelése problémás, valamint a túl nagy forgalom könnyen túlterhelheti őket.
Host alapú IDS-ek (Host based IDS, HIDS)
A host alapú IDS-ek az adott számítógépen beszerezhető információkat használják fel. Valójában az alkalmazás alapú IDS-ek a host alapúak részhalmaza. Ez egy kiváló hely számukra pontos információk szerezésére arról, hogy melyik felhasználó illetve processz próbál nem épp legitim módon extra jogosultságokhoz jutni. Továbbá itt elcsíphető a titkosított hálózati kapcsolatok forgalma is még a titkosítás előtt ([3]). Mivel az IDS a védeni kívánt rendszeren fut, egyúttal biztonsági kockázatot is jelent, mert az IDS is tartalmazhat sebezhető pontot, amellyel esetlegesen az egész rendszert meg lehet bénítani.
Alkalmazás alapú IDS-ek (Application based IDS, AIDS) Az alkalmazás alapú IDS-ek egy speciális része a host alapú IDS-eknek, amelyek egy adott programon belül elemzik az eseményeket. Legtöbbjük az alkalmazás által írt naplófájlból nyeri ezeket az információkat.
Honeypotok (mézescsuprok) Olyan gépek a hálózatban, amelyeknek semmiféle feladatuk sincs, csupán csaliként szolgálnak. Ebből következően az ilyen gépek felé irányuló mindenféle kapcsolódási kísérlet csak valamilyen gyanús tevékenység eredménye lehet ([4]).
5.2. Információelemző módszer szerint
5.2.1. Anomáliák detektálása
Az anomáliadetektorok felismerik a rendellenes, szokatlan magatartást egy adott gépen vagy a hálózaton. A működésük azon a feltevésen alapul, hogy a támadás különbözik a "normális" (legitim) működéstől, ezért detektálható egy olyan rendszerrel, amely felismeri a különbséget a kettő között. Az anomáliadetektorok profilokat készítenek, amelyek reprezentálják a felhasználók, számítógépek és hálózati kapcsolatok normális viselkedését. Ezek a profilok egy normál működésű időtartam alatt gyűjtött adatok alapján készülnek. A detektorok összegyűjtik az események adatait, és változatos módszerekkel megállapítják, hogy a figyelt tevékenység eltér-e a szokásostól.
5.2.2. Az anomáliadetektálásra használt módszerek és technikák:
- Küszöbszint érzékelés: a felhasználók egyes tulajdonságai és a rendszer viselkedése számokban van kifejezve, például a felhasznált CPU idő, adott időtartam alatt megnyitott fájlok száma, stb. Ez az érték lehet statikus vagy heurisztikus (azaz úgy tervezve, hogy cserélje az aktuális értékekre, ha elévülnek).
- Statisztikai mérések: ide tartoznak a paraméteres - ahol az ábrázolt tulajdonságok eloszlásáról feltételezik, hogy egy bizonyos mintára hasonlítanak - és a nem paraméteres mérések is, ahol az ábrázolt tulajdonságok eloszlásait a régebbi adatok kiértékelésével, határozzák meg. Ez utóbbi folyamatban az elévülést is figyelembe veszik.
- Szabály-alapú mérések, amelyek megegyeznek a paraméter nélküli statisztikai módszerekkel abban, hogy a megfigyelt adatok mintázatok (patterns) alapján kerülnek elfogadásra, viszont különböznek abban, hogy ezek a mintázatok szabályokként vannak megadva, nem számszerű mennyiségekkel.
- Egyéb módszerek, beleértve a neurális hálózatokat, genetikus algoritmusokat, és az immunis rendszermodelleket is.
Sajnos az anomáliadetektorok és a rájuk épülő IDS-ek gyakran produkálnak nagyszámú téves riasztást, mert a felhasználók és a rendszer viselkedése nagyon változatos lehet. Ezek ellenére a kutatók állítják, hogy ezek az anomáliadetektálásra épülő IDS-ek képesek új támadási formákat is felismerni, ellentétben a szignatúra-alapú IDS-ekkel. Továbbá, néhány anomáliadetektor képes olyan kimenetet produkálni, amelyet a visszaélés-detektálók is hasznosíthatnak.
5.2.3. Visszaélés (misuse) detektálás
A visszaélés-detektálók analizálják a rendszer aktivitását olyan események, illetve eseménysorozatok után kutatva, amelyek illeszkednek egy előre definiált, ismert támadást leíró mintára. Ahogyan a mintázat illeszkedik egy ismert támadás "signature"-nek nevezett mintázatára, úgy hívják ezt is néha "signature" alapú detektálásnak. A visszaélés-detektálók legáltalánosabb formáját a kereskedelmi termékekben használják, ahol minden egyes eseményt összehasonlítanak a támadások szignatúráival. Ezen kívül vannak kifinomultabb megoldások is a visszaélések detektálásra ("state-based", állapotalapú analizálási technikák), amelyek egyetlen nyomból képesek felismerni támadások egy egész csoportját. Előnyei, hogy nagyon hatásosan érzékeli a támadásokat hamis riasztások nélkül, valamint gyorsan és megbízhatóan detektálja a különleges támadásokat és technikákat. Hátrányai közé tartozik, hogy csak a már ismert támadásokat képes érzékelni, és ajánlott rendszeresen frissíteni az adatbázisát
6. Jövőbeli IDS-ek
Napjainkban a behatolásérzékelő rendszerek irányába történő kutatásokban egyre nagyobb szerepet kap a mesterséges intelligencia és az adatbányászat, mint kapcsolódó tudományág. A mesterséges intelligencia eredményeit főként az analizálással, az adatbányászatot pedig leginkább az aggregálással és korrelálással kapcsolatosan lehet megemlíteni. Ezen kívül fontos szerepet kap még a gépi tanulás, amellyel megoldható az igen változatos (számítógépes és humán) környezetekhez való alkalmazkodás kérdése.
Az 1998-as DARPA IDSE program által kitűzött verseny első három helyezettjének mindegyike valamilyen döntési fán alapuló behatolásérzékelő rendszer lett ([5]).
7. Viterbi algoritmus
Korábban a legtöbb IDS képességét csupán a felismerési arány javításának irányába fejlesztették, s emiatt nem voltak képesek a behatolások okainak és forrásának kiderítésére. Amikor tehát betörtek egy rendszerbe - függetlenül attól, hogy az IDS észrevette-e, vagy sem - sok időt vett igénybe a válaszintézkedés kialakítása. Ráadásul nehéz kideríteni a behatolási kísérletek típusát, különösen egy speciális rendszer esetén.
Ja-Min Koo és Sung-Bae Cho tanulmányában a Sun Solaris operációs rendszer Alapszintű Biztonsági Modulja (BSM - Basic Security Module) által generált audit adatokat folyamatosan ellenőrzik a behatolási kísérletek felderítésére, s amikor észlelnek egy újat akkor Viterbi algoritmussal ([8]) összehasonlítják a jelenlegi és a korábbi behatolások állapotszekvenciáit, hogy kiderítsék a behatolás típusát.
Az anomáliaészlelő rendszerek 4 fő megközelítést alkalmaznak, ezek sorban: szakértői rendszerek (A), neuronhálózatok (B), statisztikai megközelítés (C), illetve a rejtett Markov modellre épülő (D) változat. A legtöbb IDS a statisztikai módszert használja, mely olyan információkat vesz figyelembe, mint pl. a be és kijelentkezési idő, a rendszer kihasználtsági szintje, illetve a kiadott parancsokat összehasonlítja a korábbi parancsmintákkal, melyeket normál használat mellett rögzítettek. A rejtett Markov modellel a rendszerhívási eseményeket jobban le lehet írni, mint bármi mással, de hátránya, hogy a normál viselkedés modellezése sokáig tart. Ez utóbbi problémára azonban megoldás a rendszer teljesítményének növelése, illetve a tanítási adatok különféle technikákkal történő redukálása.
7.1. A behatolások típusai
A behatolók fő célja, hogy adminisztrátori jogosultságokat szerezzenek, melynek fő eszköze a puffer-túlcsordulási hibák kihasználása. A behatoló leggyakrabban egy általános felhasználói azonosítót használ, mely ritkán használt, vagy nincs jelszóval védve s erről a szintről lép feljebb a rendszergazdai szintig a hiba kiaknázásával. Az általános behatolási típusokat Markus J. Ranum egy nyílt forráskódú tűzfal fejlesztője osztályozta, majd a CERTCCKR később 10 osztályba sorolta őket. A 4 leggyakoribb típus a puffer-túlcsordulás kihasználása, a szolgáltatás-megtagadási (Denial of Service - DoS), a beállítási hiányosságokat kihasználó, s a programokban lévő hibákat kiaknázó támadás.
- A puffer-túlcsordulási hibákra irányuló támadás ellen védekezni bonyolult, mivel az egyes programok végrehajtási-sorát és memóriafoglalási struktúráját is ismerni kell, ezen felül a memória és a verem szerkezete operációs rendszerenként eltérő. Tetézi a helyzetet, hogy az ilyen hibákat kihasználó programok forráskódja gyorsan terjed az Interneten, bárki letöltheti és lefordíthatja, következésképp széleskörűen alkalmazzák őket.
- A programokban lévő hibák szintén gyakoriak, mivel a programozásuk során is követnek el hibákat, illetve sűrűn előfordul, hogy olyan felesleges jogosultságokkal indítják őket, melyre a működésükhöz nincs szükség. Ez utóbbi azért gond, mert ha sikeresen kihasználják az esetleges hibát, akkor a behatoló eleve arról a jogosultsági szintről tud parancsokat kiadni melyen a program futott.
- A beállítási hiányosságok, hibák jelenthetik a legegyszerűbb utat a behatolásra, mivel ebben az esetben gyakran még parancsfuttatásra sincs szükség, hiszen eleve futnak olyan szolgáltatások, melyeken keresztül könnyen el lehet érni a rendszert.
- A szolgáltatás-megtagadási támadások célja az előzőekétől annyiban tér el, hogy nem jogosultságszerzés a cél, hanem egy kiszolgáló működésének oly mértékű lassítása, leállítása, hogy az általa nyújtott szolgáltatást a felhasználók ne érjék el.
7.2. A Solaris BSM rendszere
A különféle Unix rendszerek a naplóinformációkat általában egységesen a /var/log könyvtárban helyezik el, mely nagyon jó akkor, amikor vissza akarunk keresni valamit, azonban egy sikeres behatolás esetén könnyen le lehet őket törölni. A BSM viszont a rendszerhívások szintjén készít audit adatot, mely ezáltal jól használható a behatolások detektálására. Ezen adathalmaz része többek között egy egyéni felhasználói azonosító, melyet minden felhasználó megkap a bejelentkezéskor, s melyet minden általa indított folyamat örököl. Ezáltal lehetővé válik az IDS számára, hogy egyértelműen beazonosítsa, hogy melyik felhasználó idézett elő egy bizonyos eseményt, még akkor is, ha közben más felhasználóként is bejelentkezik, például a 'su' parancs használatával. Az audit rendszer az adatokat alapállapotban bináris formában tárolja, azonban a Sun kibocsátott egy praudit nevű eszközt, mely előállítja a bináris adathalmaz emberek számára könnyen értelmezhető szöveges megfelelőjét. Az ismertetésre kerülő algoritmusok is ezzel az ASCII formátumú adathalmazzal dolgoznak, mivel a kódolás és a hibajavítás így sokkal könnyebb, habár az átalakítás nyilvánvalóan lassítja a folyamatot. Amikor pedig az algoritmus már bizonyítottan jól működik, ki lehet terjeszteni a képességeit a bináris adathalmaz közvetlen feldolgozására, s ezáltal ez a hátrány is megszűnik. Az adathalmaz szerkezetét a 2. ábrán láthatjuk.
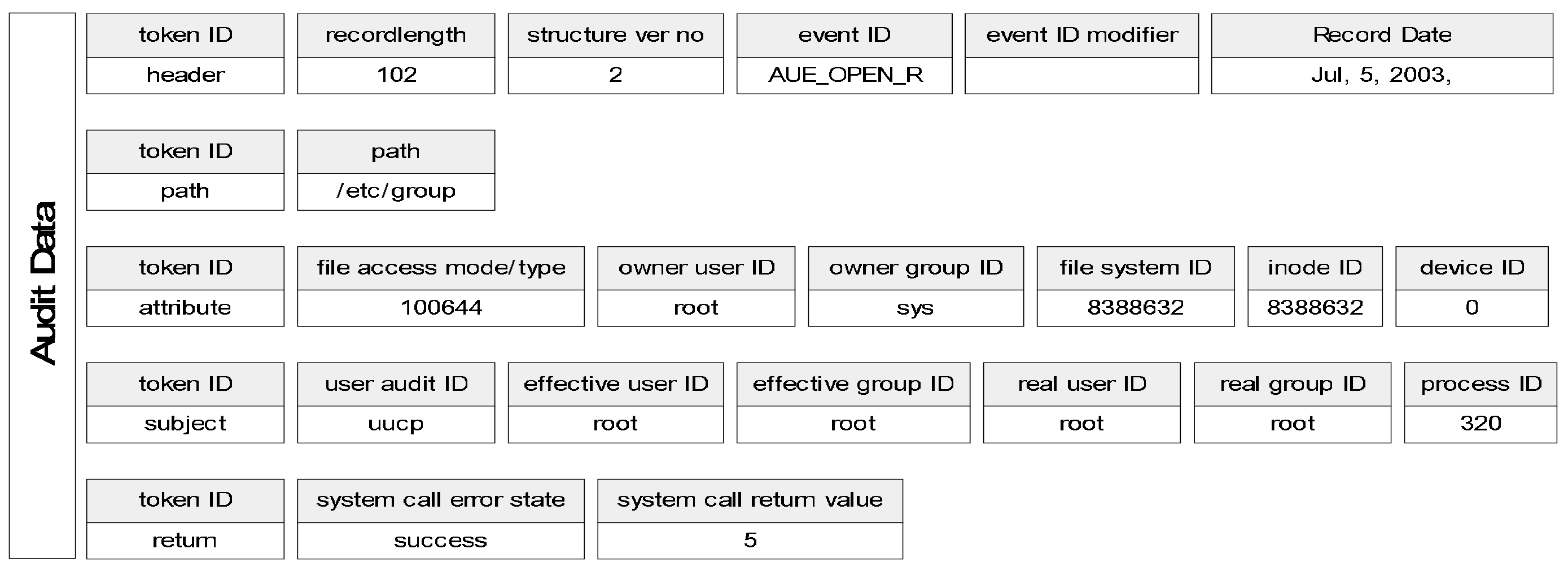
2. ábra: A BSM szerkezete
7.3. A módszer
Egy rejtett Markov-modellel (HMM, Hidden Markov Model) működő IDS a normál audit adatokat összegyűjtve illetve azokat tömörítve készíti el egy adott rendszer normál viselkedési modelljét. A behatolást az audit adatok kiértékelésével detektálja, a típusát pedig Viterbi algoritmus segítségével. A 3. ábra mutatja a teljes rendszer struktúráját.
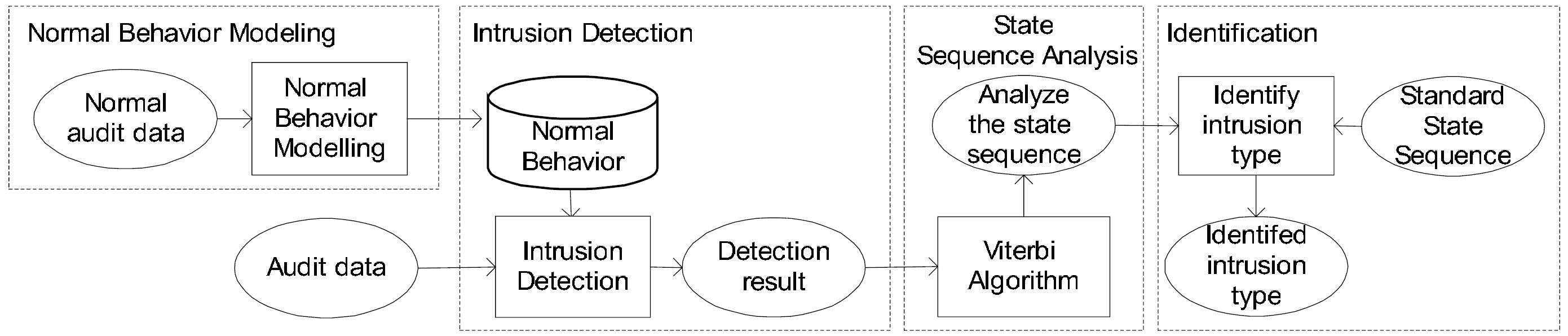
3. ábra: A rendszer struktúrája
A módszer 4 részből áll: a normál viselkedést modellező, a behatolás-detektáló, az állapotszekvencia-analizáló, és a típusmeghatározó részből. A Sun BSM megfelelő alapot nyújt a behatolás-detektáló rész számára, mivel például egy puffer-túlcsordulási támadást elszenvedett program jelentősen más rendszerhívási eseményeket állít elő, mint egyébként. Mivel a rendszer a normál használat közben készült modellhez hasonlítja az eltéréseket, a behatolások detektálása megfelelő.
7.4. A normál viselkedés modellezése
A rendszer audit adatainak modellezése a HMM segítségével történik, melyet széles körben alkalmaznak a beszéd és képfelismerés területén is, mivel a szekvenciák modellezésére nagyon jól használható. A HMM paramétere a ? a ?=(A,B,?) összefüggéssel írható le. Egy HMM az alábbiakkal jellemezhető: egy Q állapothalmazzal, egy V lehetséges megfigyelési szimbólumhalmazzal, a megfigyelési szimbólumok számával, ez az M, az A-val jelölt állapot-átmeneti valószínűségi eloszlással, B jelöli a megfigyelési szimbólumok valószínűségét, a kezdeti állapot-eloszlást pedig a ?. Jelen estben a V az összes rendszerhívási esemény halmazát jelenti, az M az események számát, a T pedig megfigyelési időtartamot. Az itt használt HMM egy balról jobbra haladó modell, mely az ideiglenes jelek modellezésére jobb, mint bármely másik. A normál viselkedés modellezése a HMM paramétereit meghatározza, mégpedig úgy, hogy ha a bemeneti szekvenciát O-val jelöljük, akkor a P(O|?) valószínűség maximális legyen. Mivel erre semmilyen analitikus megoldás nem kínálkozik, így egy iteratív módszert: a Baum-Welch algoritmust alkalmazva. A 4. ábrán egy balról jobbra haladó HMM látható.
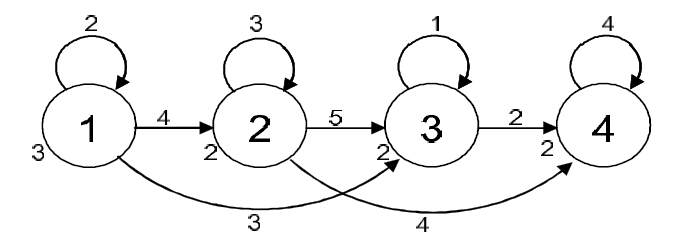
4. ábra: Négy állapotú balról-jobbra haladó HMM
7.5. Behatolás-detektálás
A rendszer állapotának megállapítása az előbbi valószínűség kiértékelésével történik. Azt a valószínűséget, hogy a O1, O2 ...Ot jelű résszekvenciák egy qi állapotban maradnak at(i)-vel jelöljük.
![]()
Eszerint a képlet szerint at(i) azt a valószínűséget jelenti, hogy egy bemeneti sorozat összes eleme sorban kiértékelésre került és a végállapot elérte i-t. Az alábbi eljárással lehet at(i)-t összegezni:
Inicializálás:
![]()
Indukció:
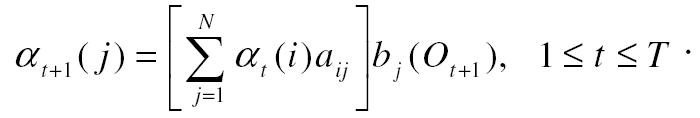
Végül:
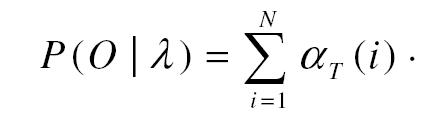
Ha a kiszámított P(O|λ) érték egy meghatározott küszöbön belül van, akkor behatolás történt. A behatolás típusának meghatározásához szükség van a rendszeresemények állapotszekvenciáinak analizálására. A HMM ilyenformán nem nyújt megoldást az állapot-szekvenciák kezelésére, azonban Viterbi-algoritmussal a legvalószínűbb események esetén megbecsülhetők. Egy adott szimbólumsorozat mellet Viterbi-algoritmussal megtalálható a legvalószínűbb állapot-átmeneti út egy állapotdiagramon. Ezt a megoldást a beszéd és karakterfelismerés területén is alkalmazzák, ahol a megfigyelési szimbólumok szintén HMM-mel vannak modellezve. Az 4. ábra HMM-jén alapuló Viterbi-algoritmus az 5. ábrán látható.
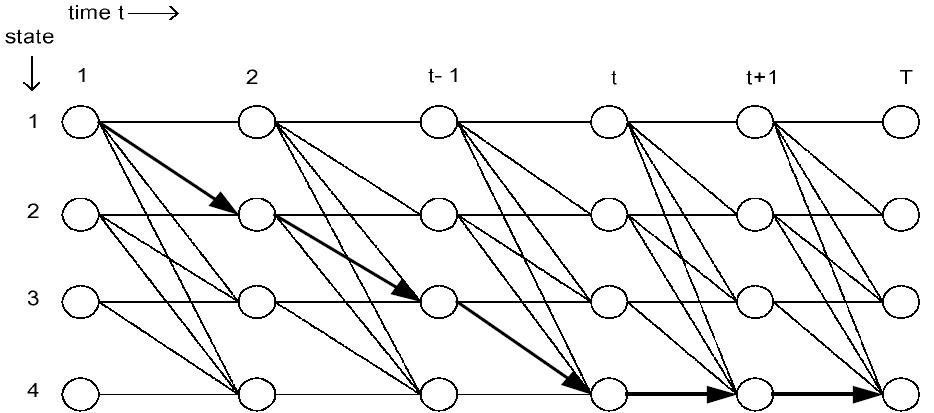
5. ábra: A Viterbi algoritmus folyamata
A balról jobbra haladó HMM-ben átmenet csak balról jobbra haladva lehetséges és csak egy állapotot lehet kihagyni, ezért az egyetlen állapotátmenet: aij, aij+1, aij+2. A 4. ábrán például, mivel a legnagyobb kezdeti állapot-eloszlással rendelkező állapottal kell kezdenünk ezért az 1 állapot 1 idő helyen kezdünk és a legnagyobb átmeneti valószínűséggel rendelkezővel folytatjuk az 1,2,3,4 állapot, 2 idő helyek közül. Az algoritmus folyamata:
Inicializálás:
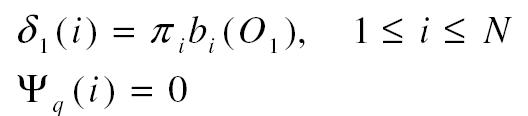
δt(i) annak a valószínűsége, hogy a O1 szimbólum a t=1 időben a i állapotban fordul elő. A ψt(j) változó tárolja az optimális állapotokat. A 3. ábrán látható, hogy a fenti δt(i) jelöli ki a számokat, melyek az állapotok mellett állnak. A δ1(1)=3, δ1(2)=2, δ1(3)=2, δ1(4)=2.
Rekurzió:
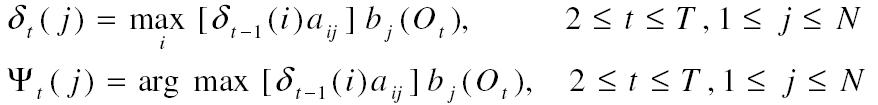
δt(i) jelenti az összegzett súlyát annak, amikor i állapotban és t időben tartózkodunk a folyamat alatt, ψt(j) jelöli a t-1 időben lévő állapotot, ahonnan a legkisebb a költsége az állapot-átmenetnek j állapotba t idő alatt. A 3. ábrán δ2(1)=5, δ2(2)=7, δ2(3)=6, δ2(4) nem meghatározott, ezért ψ2(2)=2.
Végül:
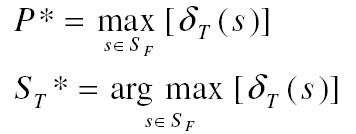
Az utolsó T időben N db valószínűség van: δt t=1,2,...,N. Ezek közül a legnagyobb valószínűség lesz a jelölt optimális állapot-szekvenciának. S*T tárolja a megfelelő állapotokat. A záró feladat visszakövetni a kezdeti állapotba a ψt változót követve.
Visszakövetés:
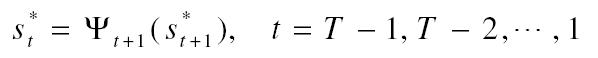
Mikor ez kész, akkor megvan az optimális állapot-szekvencia '1-2-3-4-4-4' ahogyan az 5. ábrán is látható.
7.6. A behatolás típusának megállapítása
A visszakövetés után a jelenlegi behatolás állapot-szekvenciái összehasonlításra kerülnek minden behatolási típus átlagos állapot-szekvenciájával Euklideszi távolságot használva. A képlet:
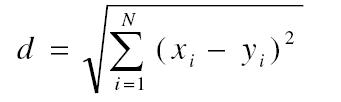
xi-vel jelöljük a jelenlegi behatolás állapotsorát, yi-vel az eddigi behatolásokét. Minél kisebb a d, a hasonlóság annál nagyobb. Ezért a behatolás típusa a legkisebb értéket adóéval azonos.

1. táblázat: Puffer túlcsordulási hibák állapot-szekvenciái
(A: xlock, B: lpset, C: kcms_sparc)
A tanulmányban megjelenő biztonsági hibákat nem fordítjuk, illetve nem magyarázzuk, mivel már kijavításra kerültek, illetve konkrét programokhoz kapcsolódnak.
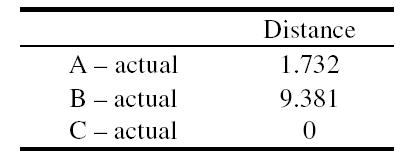
2. táblázat: A hasonlóság a jelenlegi (actual) behatolással
7.7. Kísérletek
A normál viselkedés modellezéséhez 6 végzős hallgató 2 heti munkája során készült - összesen 13 megabyte-nyi, 160448 eseményt tartalmazó - BSM audit adat lett felhasználva. A megfigyelt gépeken Sun Solaris 7 operációs alatt főként szövegszerkesztő, fordító és a felhasználók által írt saját programok futottak. Ezután különféle puffer-túlcsordulást kihasználó és szolgáltatás-megtagadási támadásoknak lett alávetve a rendszer. A támadási típusok és a próbálkozások száma a 3. táblázaton látható.

3. táblázat: Behatolási típusok
7.8. Eredmények
A kísérletek különféle számú állapottal és megfigyelési hosszal is le lettek folytatva. A 4. táblázat mutatja a HMM alapú IDS eredményeit. A kísérlet során a küszöbérték -20.83 volt, mely a téves riasztások számát a lehető legkisebbre csökkenti. A 6. ábrán láthatóak az egyes behatolások állapot-szimbólum szekvenciái – az értékek 30 futtatás után értendőek.
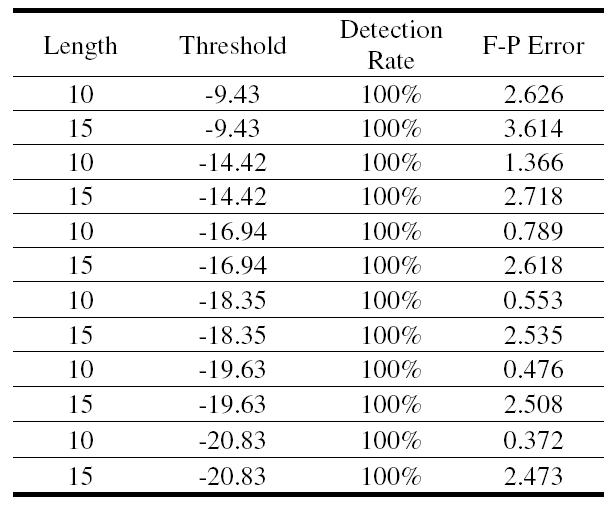
4. táblázat: A HMM alapú IDS teljesítménye
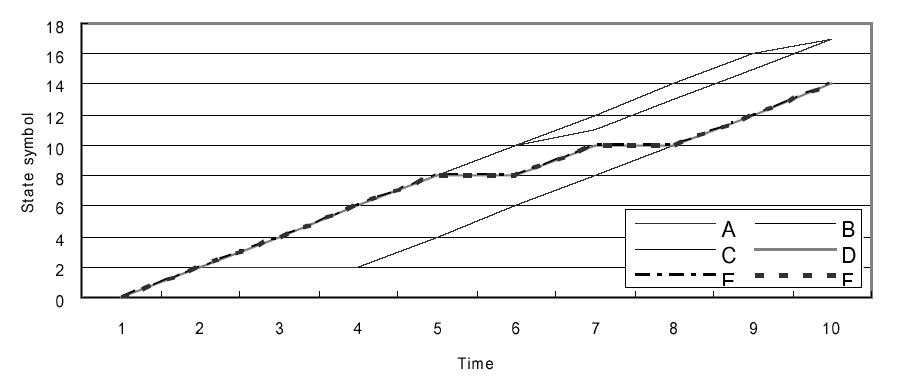
6. ábra
A behatolás típusának észlelésre is le lett tesztelve az 5. és a 6. táblázat mutatja az eredményeket.
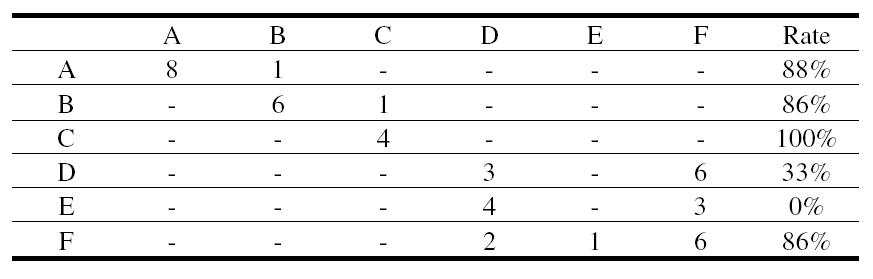
5. táblázat
A,B,C,D,E és F jelöli a támadási típusokat, sorrendben: xlock halom túlcsordulás, lpset túlcsordulás, kcms_configure túlcsordulás, folyamatgenerálás, a merevlemez megtöltésére illetve a memória teljes lefoglalására irányuló támadások. Az oszlopok jelölik az alkalmazott, a sorok az észlelt támadási típusokat. Az eredmények azt mutatják, hogy a puffer-túlcsordulásra irányuló támadások azonosítása hatékony, azonban DoS támadásokat - sajátosságaik miatt – nehéz pontosan azonosítani. Az elemzések során kiderült, hogy ennek oka az, hogy állapot-szekvenciáik nagyon hasonlítanak egymásra.

6. táblázat: Az eredmények átlaga
Az alkalmazott módszer a folyamatgenerálást 60%-ban memória túlterhelésnek észlelte, a merevlemez betelítésére irányuló próbálkozást pedig 40%-50% arányban folyamatgenerálásnak illetve memória túlterhelésnek. Ezért e három típus esetén a hasonlóság Euklideszi-távolság alkalmazásával meg lett vizsgálva, s minden párosításban 0 lett az eredmény, vagyis matematikailag is belátható, hogy nagyon hasonlóak.
A felismerésre ezenkívül természetesen az állapotok számának is hatása van. 5, 10 és 15 állapot esetén a sorozatok megegyeznek, tehát nem lehet felismerni a különféle típusokat, 20 állapot esetén azonban mindegyik típus más és más, vagyis megkülönböztethető.
8. Döntési fa
Az anomáliákat észlelő IDS-ek számos MI technikát alkalmazva modellezik a normál viselkedést. Azonban egyik sem tökéletes megoldás, azaz csak véges számú behatolási típust észlelnek, és mindnél előfordul vakriasztás is, azonban kombinálva őket jobb eredmény érhető el. Az itt ismertetésre kerülő módszer ([7]) egy gépi tanulási technikát a döntési fát alkalmazva teszi ezt. A másik tanulmányhoz hasonlóan itt is a Solaris BSM audit adatai kerülnek kiértékelésre. A rendszer struktúrája a 7. ábrán látható.
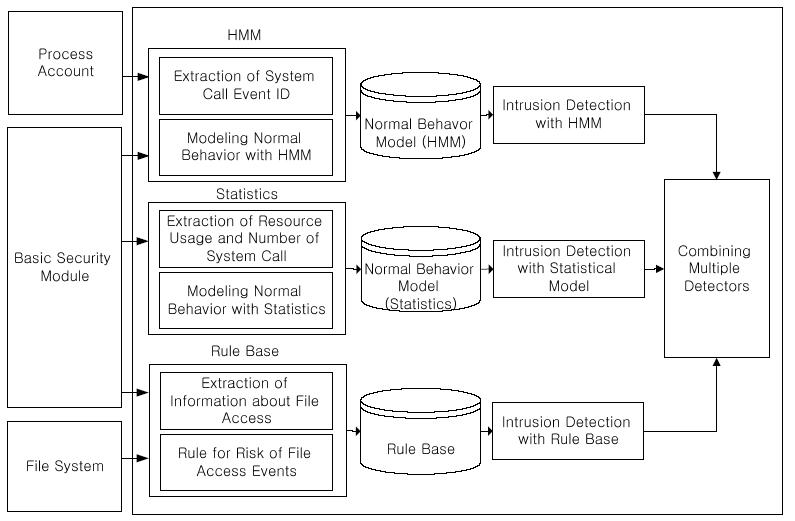
7. ábra: A rendszer struktúrája
8.1 Az erőforrás használat és a rendszerhívások statisztikája
Szinte minden Unixon alapuló operációs rendszerben elérhető a folyamatok CPU idejét, memória-használatát, I/O használatát stb. tartalmazó audit adathalmaz (PACCT), melynek figyelésével a túlzott erőforrás-használatot előidéző behatolások, - mint a DoS - észlelhetők. Léteznek olyan támadási formák is, amelyek ezzel a módszerrel nem észlelhetők, mivel például a folyamattáblát próbálják betelíteni. Általában az ilyen események azonban nagyszámú rendszerhívást okoznak, ami viszont más módszerrel ellenőrizhető.
A következő statisztikai módszer az elterjedt NIDES (Next-generation Intrusion Detection Expert System – Következő-generációs Behatolás Érzékelő Szakértői Rendszer) -ben is alkalmazott eljárás módosított változata. A rendszer minden egyes audit rekordhoz generál egy T-vel jelölt statisztikai értéket, ami összegzi felhasználó korábbi viselkedésében lévő abnormalitás fokát. Magas T érték abnormális viselkedésre, zérushoz közeli érték normál viselkedésre utal. A PACCT esetén S jelöli az egyes mutatókban, T pedig a naplózott adatok összegzéségében tapasztalható eltérést.
T=a1s1 + a2s2 + ... + ansn
sn a pontszáma, an a súlya az egyes mért paramétereknek. Minden S statisztika egy megfelelő Q statisztikából van transzformálva, így a különféle jellemzők abnormalitásai összehasoníthatók. Q jelöli a közeli múltból származó audit adatokat. Hogy a Q-t S-é lehessen transzformálni minden Q értékről egy normál log készül, ezt összehasonlítva a jelenlegi Q értékkel eldönthető, hogy mennyire tér el a jelenlegi érték a régebbiektől. Kis Q érték azt jelenti, hogy közelmúlt hasonlít a régebbi viselkedésre, nagy Q érték természetesen elérést mutat. Ha k-val indexeljük a megfelelő audit adatokat t k az az idő ami a k-adik és a legújabb audit adatok rögzítése között eltelt, r a bomlási ráta, Dk a változás a k+1-edik és a k-adik adat között. Q definíciója:
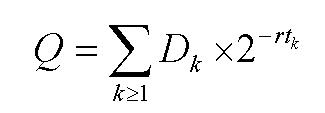
8.2. A fájlelérési események
Általában a támadások magas biztonsági szintű fájlokra irányulnak, mivel például ha a behatoló egy SETUID joggal rendelkező fájlt futtatni tud, onnan esetleg magasabb szintre tud lépni, a rendszer szempontjából kritikus fájlok elolvasásával pedig fontos információkat tud szerezni. Tehát, ha egy átlagos felhasználó magas biztonsági szinten lévő fájlokat ér el, az mindenképpen gyanús. A legismertebb fájl hozzáférési biztonsági házirend a Bell-LaPadula (BLP) modell. Valamilyen információ elérése estén három attribútum van: tárgyi, objektum és hozzáférési. A tárgyi vonatkozik a felhasználóra vagy a programra, az objektum magára a fájlra, a hozzáférési pedig az elérés módjára: írás, olvasás, futtatás, stb. Elérést a modell csak a tárgy engedélyének és az objektum besorolásának összehasonlítása után a tárgy megfelelő hozzáférési attribútuma esetén enged. A tárgyak és objektumok 4 biztonsági kategóriába vannak sorolva: rendszer, adminisztrátor, felhasználó, illetve vendég. Az elérési esemény a kockázat alapján a 21 lehetséges tárgy-objektum szintkülönbség valamelyikébe kerül besorolásra. Minél nagyobb a különbség annál magasabb a kockázat, de magának az objektumnak az elérés attribútuma önmagában is számít, például, ha csak írásra és olvasásra nyitható meg egy fájl, az kisebb kockázatot jelent, mintha futtatható is.
8.3. Érzékelők kombinálása
Az alkalmazott döntési fa az egyik legelterjedtebb eszköze az induktív következtetésnek. A döntési fa megalkotása egy olyan fastruktúra felépítését jelenti, amely megbecsüli egy esemény osztályát, azaz az attribútumainak értékeit. A fa minden csomópontja meghatározza az eset valamely attribútumának tesztjét és minden ága ezen attribútumok egy lehetséges értékét. A konstruáló algoritmus a gyökértől kezdi építeni a fát és kiválasztja a legjobb következő attribútumot minden új ághoz. Az itt használt Quinlan nevéhez fűződő C4.5 algoritmus energia-entrópia alapú információelméleti megközelítést alkalmaz. Az 'oszd meg és uralkodj' elvet alkalmazva kiválaszt egy attribútumot, a tanítóhalmazt alcsoportokra bontja az attribútumok lehetséges értékei alapján, majd ezt a folyamatot rekurzívan folytatja minden alcsoporttal addig, amíg valamelyik több mint egy osztályból tartalmaz objektumot. Az így létrejött alcsoportok alkotják a leveleket. Az attribútum-választásnál használt entrópia alapú kritérium neve: nyereségi arány kritérium.
Jelöljük T-vel a csomóponthoz rendelt események osztályának csoportját. Először a T-beli események gyakoriságát kell kiszámítani, az eredmény egy Cj osztály. Ha van olyan Cj osztály, melynek gyakorisága 1 (azaz minden esemény egy valódi eseményhez tartozik), vagy egy értéknél magasabb, akkor egy levélcsomópont készül a hozzátartozó Cj osztállyal. Ha nincs nagy gyakorisági értékkel rendelkező osztály, akkor minden egyes attribútum információnyereségét ki kell számítani. Ez az érték a mérőszáma az attribútumoknak az adat-osztályozási hatékonyság szempontjából, ezért a maximális információnyereséggel rendelkező attribútum kerül kiválasztásra. Ha a kiválasztott attribútum folyamatos, akkor a fa – egy meghatározott küszöbszinttel – bináris csomópontokká, ha diszkrét, akkor az attribútum minden lehetséges értékére ágazik szét. T' jelöli a kiválasztott tulajdonságon végrehajtott teszt által előállított halmazt, mely teszt miden nem üres T' -re rekurzívan meghívódik. A T' üres a gyermek csomópont egy levél, az algoritmus:
| [Első lépés] | T osztály-gyakoriságának kiszámítása |
| [Második lépés] | ha csak 1 vagy kevés eset van
adj vissza levelet
különben készíts egy N döntési csomópontot |
| [Harmadik lépés] | minden egyes A attribútumra számítsd ki a legjobb A attribútumot |
| [Negyedik lépés] | ha A folytonos találj Küszöbszintet |
| [Ötödik lépés] | minden T'-re a szétágazó T-k közül ha T Üres N gyermeke egy levél különben N gyermeke = készíts fát |
A döntési fa tanításához egy megjelölt támadásokkal kevert, főként normál viselkedést naplózó audit halmaz lett összegyűjtve. A négy detektor mindegyike megvizsgálja ezt, s az eredményük lesz a döntési fa tanító halmaza, olyan formátumban, melyet a fa generátora értelmezni tud. A fa készítési folyamata a 8. ábrán, az elkészült döntési fa a 9. ábrán látható.

8. ábra: A döntési fa készítése
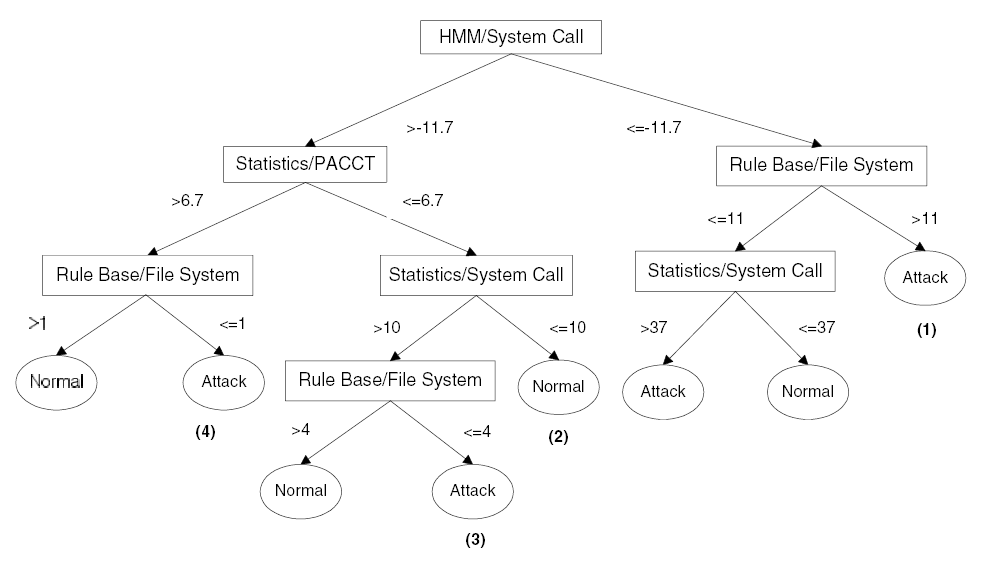
9. ábra: A döntési fa
A generátor minden levélnek egy osztályozó szabályt feleltet meg, így összesen nyolc szabályt készített, közülük négy lépett gyakran életbe.

10. ábra: A 4 gyakran alkalmazott szabály
Az 1-es szabály minden folyamatot támadásnak minősít, amely gyanús rendszerhívásokat végez és kockázatosnak minősített fájlokat ér el, ezáltal a puffer-túlcsordulásra irányuló támadások nagy részét kiszűri. A 2-es szabály az átlagos viselkedésű folyamatokat sorolja be a normál osztályba. A 3-as és a 4-es a DoS típusú támadásokat szűrik. A 3-as támadásnak nyilvánítja azokat, melyek ugyan átlagos erőforrás-felhasználást mutatnak és nem generálnak gyanús rendszerhívásokat, de nagyon nagyszámú szokványos rendszerhívást intéznek, ezáltal próbálva betelíteni a folyamattáblát. A 4-es ezzel szemben a túlzott erőforrás-használatú támadásokat szűri. Mindkét utóbbi szabály definíciójában megtalálható kisebb-mint operátor a gyanús fájlok elérésére vonatkozóan, mivel ezen típusú támadáshoz nincs szükség hozzáférni kritikus fájlokhoz.
8.4. Kísérletek
A tesztkörnyezet ugyanaz, mint a előző algoritmus esetén, itt azonban felhasználásra került még a 16470 parancs kiadásából származó 840 kilobájtnyi PACCT audit adat is, illetve a 28 megjelölt támadással kever adathalmaz. Az alkalmazott behatolási módszereket a 7. táblázat mutatja.

7. táblázat: A támadási fajták
A kísérlet 3 fázisban folyt (11. ábra). Először az egyes detektorok külön-külön lettek tesztelve, ezután az ismertetett algoritmussal le lett generálva a döntési fa, végül a kombinált rendszerrel is meg lett vizsgálva az adathalmaz.
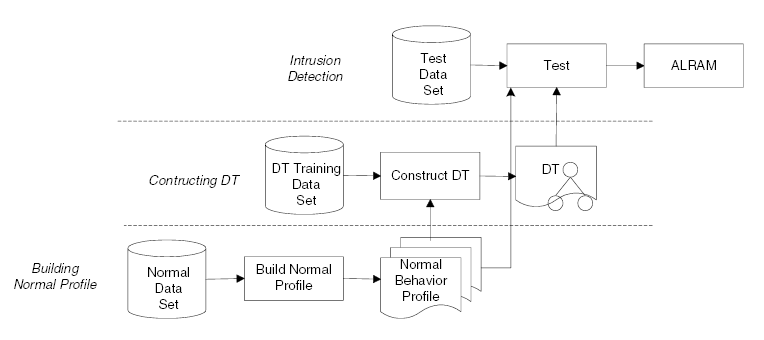
11. ábra: A kisérlet
8.5. Teljesítmények
A két legfontosabb adat az IDS -ek jellemzésénél a detektálási (detection rate) és a vakriasztási (false-positive error) arány. Minden olyan támadást érzékeltnek tekintett, melynek akár csak egy folyamatát is behatolásként azonosította a rendszer. A vakriasztási szint pedig a rosszul besorolt folyamatok aránya. A teljesítmény megjelenítése ROC görbe segítségével történik, amely akkor ábrázolja az arányok változását, amikor egy módosítható paraméter is változik, ez jelen esetben a kiértékelési küszöbszint.
Az adott detektálási módszer teljesítményének numerikus mérésére a megkülönböztetési készség szolgál, amely az az átlagos intenzitáskülönbség amit a jelet tartalmazó illetve nélkülöző minta között érzékel a megfigyelő. Annál nagyobb az értéke minél jobb a detektálási (H) és minél kisebb a vakriasztási (F) arány. Definíciója: d' = z(H) – z(F), ahol z a normál eloszlás inverze.
8.6. Eredmények
A kísérletek eredménye, hogy az egyes detektorok külön-külön rossz eredményeket érnek el a mérés karakterisztikája és a modellezési módszerek miatt. Az egyes detektorok teljesítményét a legkedvezőbb paraméterekkel vizsgálva – 3 állapot, a HMM bemenetei szekvenciájának hossza 8, és a súlyozott erőforrás- használati arány 2:1:2 (CPU, memória, I/O) – az derül ki, hogy egy adott detektálási ráta fölött a vakriasztás drasztikusan megnő (12. ábra.) A lekedvezőbb paraméterek értékei korábbi kísérletek eredményéből származnak.
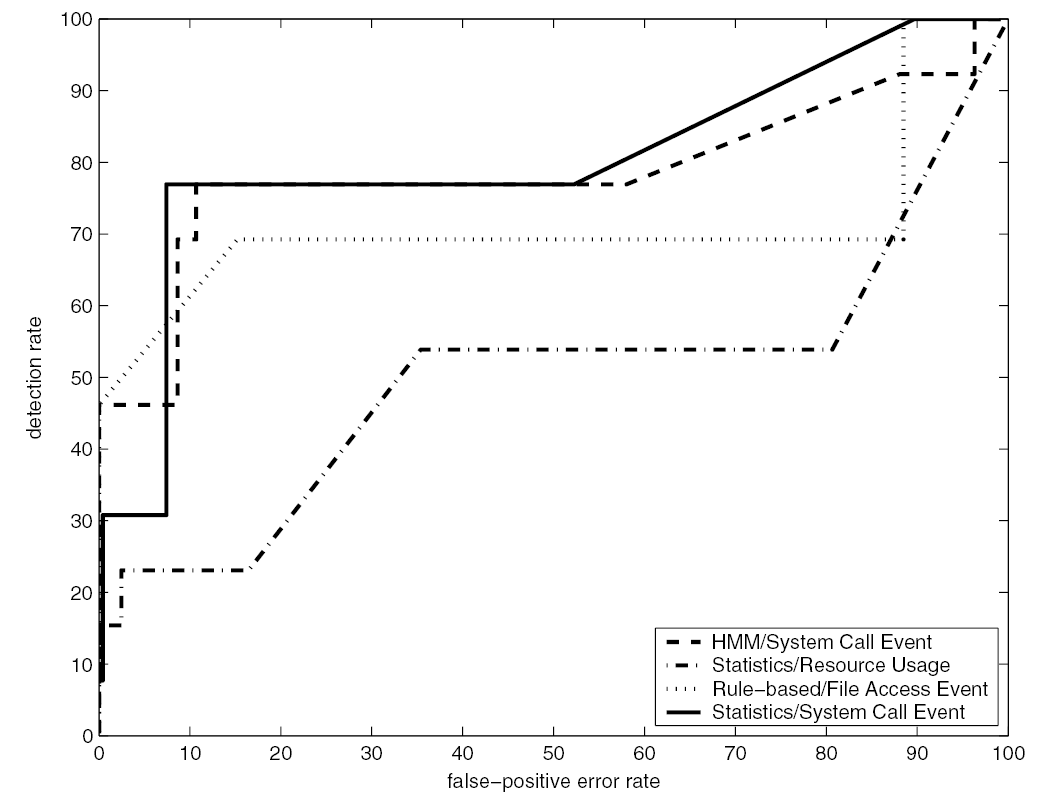
12. ábra: ROC görbe
Az elkészült döntési fával kombinálva az egyes detektorokat – ugyanolyan paraméterekkel, 100% detektálási arány mellett – egyértelműen látszik, hogy rendkívüli mértékben csökken a vakriasztás.
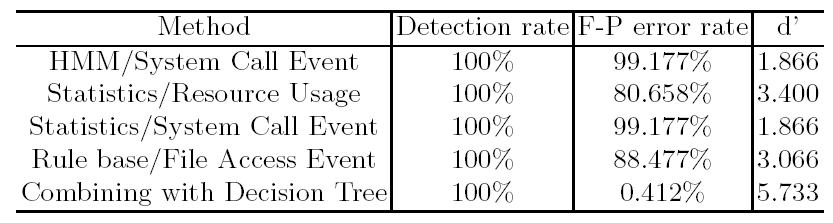
8. táblázat: A detektálási módszerek összehasonlítása
A döntési fának mindezen felül az a nagy előnye, hogy a felhasználó vizuálisan is megértheti az általa generált szabályokat. A jövőben nagyobb adathalmazzal – például a DARPA IDSE programjából – pontosabban lehet – és valószínűleg fogják is – vizsgálni az ismertetett módszert, illetve a többmodellű rendszerek számításigényét is.
9. Konklúzió
Mivel ez a témakör viszonylag új és teljesen szerteágazó, ezért e tanulmány keretein belül csak néhány, reményeink szerint a jövőre nézve is jelentős módszert tudtunk áttekinteni. Véleményünk szerint a jövőben a döntési fák további vizsgálata lesz a kutatások egyik fő célpontja, mivel használatával hatékonyan kombinálhatóak az egyébként különálló megoldások.
10. Felhasznált irodalom:
- Steven J. Scott: Threat Management: The State of Intrusion Detection
http://www.snort.org/docs/threatmanagement.pdf, 2002. aug. 9. - Rebecca Bace and Peter Mell: Intrusion Detection Systems
http://www.snort.org/docs/nist-ids.pdf - Solar Designer: Designing and Attacking Port Scan Detection Tools
http://www.phrack.org/show.php?p=53&a=13
http://www.inexonis.sk/eurohack/index.php?aid= - Lance Spitzner: Honeypots - Definitions and Value of Honeypots...
http://www.infosecwriters.com/texts.php?op=display&id=80
http://www.inexonis.sk/eurohack/index.php?aid=208 - Dong Song, Malcolm I. Heywood, and A. Nur Zincir-Heywood: A Linear Genetic Programming Approach to Intrusion Detection
E. Cantú-Paz et al. (Eds.): GECCO 2003, LNCS 2724, pp. 2325-2336, 2003.
© Springer-Verlag Berlin Heidelberg 2003 - Stuart J. Russel - Peter Norvig: Mesterséges intelligencia modern megközelítésben, Panem-Prentice Hall, 2000
- Sang-Jun Han and Sung-Bae Cho: Combining Multiple Host-Based Detectors Using Decision Tree
T.D. Gedeon and L.C.C. Fung (Eds.): AI 2003, LNAI 2903, pp. 208-220, 2003.
© Springer-Verlag Berlin Heidelberg 2003 - Ja-Min Koo and Sung-Bae Cho: Viterbi Algorithm for Intrusion Type Identification in Anomaly Detection System
K. Chae and M. Yung (Eds.): WISA 2003, LNCS 2908, pp. 97-110, 2004.
© Springer-Verlag Berlin Heidelberg 2004 - Xian Rao, Cun-xi Dong, Shao-quan Yang: Statistic Learning and Intrusion Detection
G. Wang et al. (Eds.): RSFDGrC 2003, LNAI 2639, pp. 652-659, 2003.
© Springer-Verlag Berlin Heidelberg 2003
Az 5, 7, 8, 9 számú irodalmat az EISZ (http://www.eisz.hu/) SpringerLink szolgáltatásán keresztül értük el.
Legutóbbi hozzászólások
9 év 16 hét
10 év 5 hét
10 év 9 hét
10 év 27 hét
11 év 29 hét
11 év 34 hét
11 év 34 hét
11 év 35 hét
11 év 45 hét
12 év 16 hét